How to reset Lenovo laptop
Here's how to reset your Lenovo Laptop for Windows 10, Windows 11, or by using Lenovo OneKey
WePC is reader-supported. When you buy through links on our site, we may earn an affiliate commission. Prices subject to change. Learn more
Figuring out how to reset Lenovo laptop doesn’t have to be a laborious task. In fact, Lenovo laptops have additional functionality for this. On most laptops, there’s only one way to factory reset. But Lenovo provides an additional option to its users. It’s called OneKey Recovery.
So, the following article explains both ways of resetting a Lenovo laptop.
How to reset a Lenovo laptop using Lenovo OneKey Recovery
Lenovo laptops like the ThinkPad or the IdeaPad come with the Lenovo OneKey Recovery Mode. It allows the users to use OneKey Recovery. OneKey Recovery is activated via the Novo Button. But there’s not always physical button on the laptop. Some models have a hole in the side of the laptop, and you have to use an unfolded paper clip or a SIM ejector tool or a similar object to press this button.
Do note that resetting your Lenovo laptop to factory defaults with this method will erase all data from it, so it’s best to back up any important files on an external hard drive or flash drive.
Step
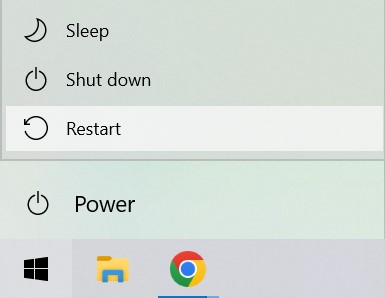
Shut down your laptop
Power off your Lenovo laptop. Do this by going to the Windows start menu and selecting the ‘Shut down‘ option.
Step
Press the Novo button located either near the power button or on the side of your Lenovo laptop, the image below shows how this should look.
Some Novo buttons require a SIM ejector tool (or unfolded paper clip) to press.

The Novo button is very effective against booting issues, and the OneKey Recovery Mode can help you with system recovery.
Step
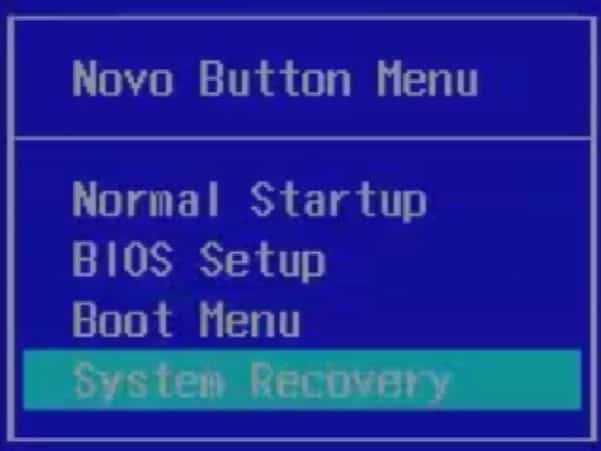
Open System Recovery
You will be greeted with the Novo button menu. Here, click the ‘System Recovery‘ option. Navigate to this with your arrow keys and press Enter to select it.
Step
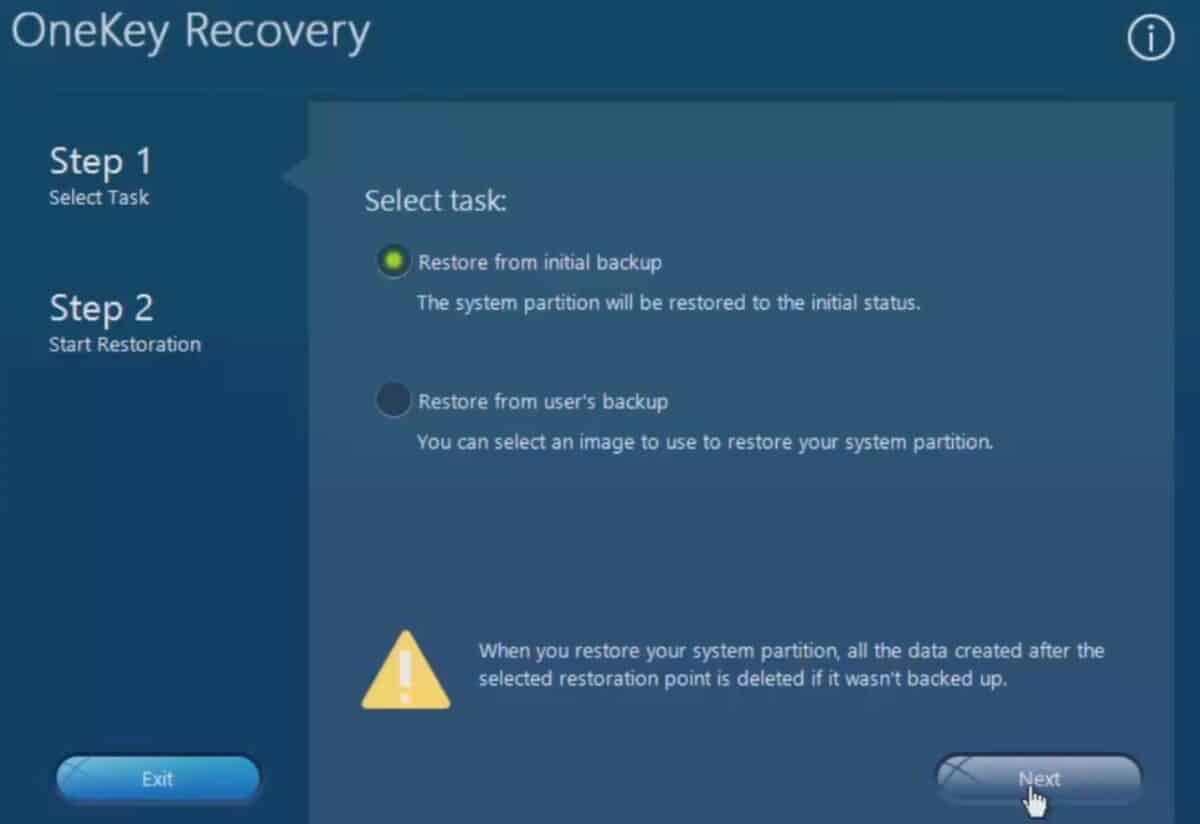
Choose restore backup
Now we choose the kind of backup method to use before resetting. For most users, you’ll want to use the ‘Restore from initial backup‘ setting. This will reset your Lenovo laptop back to it’s factory settings.
If you instead have an external backup image, you can use the user’s backup option to configure this.
Step
Start system restoration
Now it’s time to start the resetting process. If you’re certain everything is backed up correctly, you can now proceed with this step. Click ‘Start‘ and then confirm with ‘Yes‘ to reset your laptop.
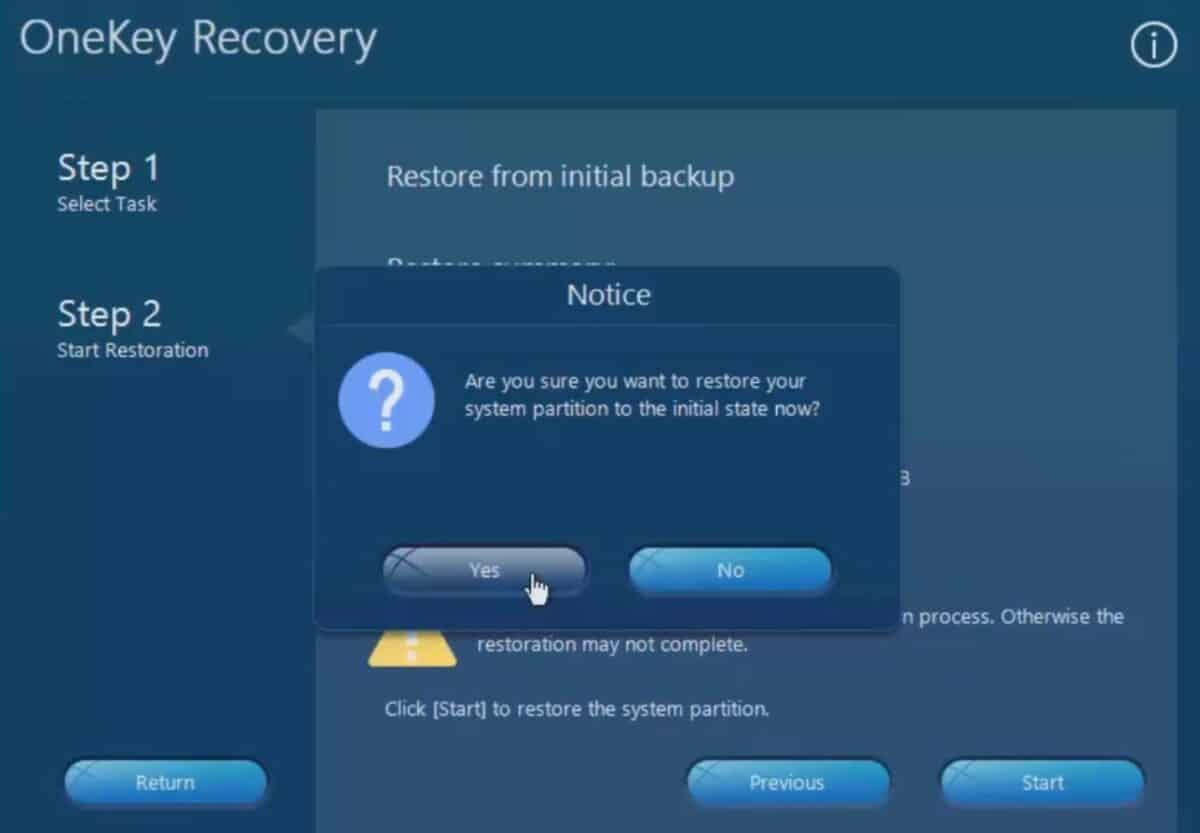
Step
Finish system restoration
Following the previous step, OneKey Recovery will be resetting your Lenovo laptop to it’s factory default settings. Let this process complete, and you’ll be notified. Simply click ‘OK‘, ‘Done‘, and then ‘Reboot‘ to restart your laptop.
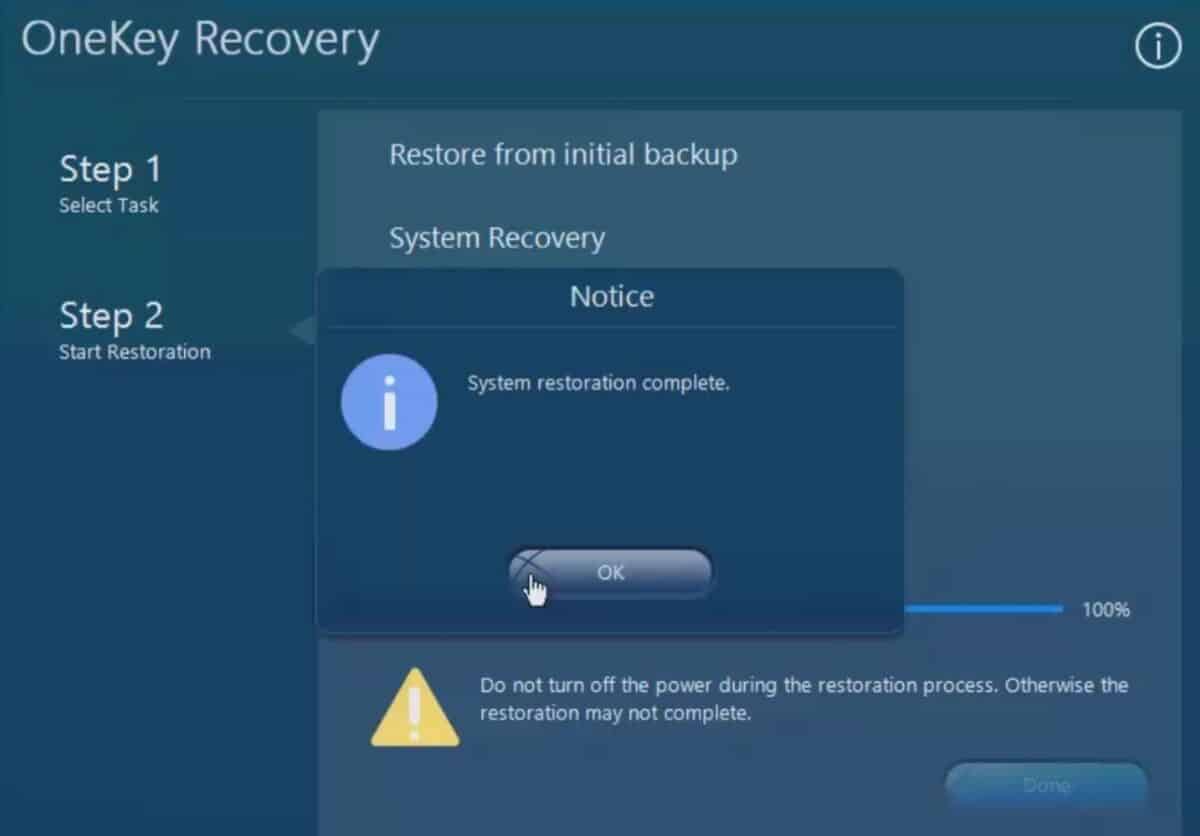
Step
Set up your laptop
Once your laptop has rebooted, you’ll be greeted with some initial set-up screens as if the laptop was brand new. This confirms that the device has been reset to it’s factory settings.
Now you’ll have to follow the process of setting your laptop back up again. This includes choosing your region, language, licensing agreement, Wi-Fi, account, and personalization options.
Go through this process as normal and you’ll be booted back into your fresh installation of Windows.

How to reset a Lenovo laptop in Windows
This is the conventional way to reset a Lenovo or any laptop for that matter. The steps are simple, but the process differs a bit between Windows 10 & 11.
For Windows 11
Follow the steps below if you are using Windows 11 on your Lenovo laptop.
- Press the Win + I keys on your keyboard to open Windows Settings.
- Select System on the left side of the window.
- Scroll down on the right side and locate Recovery. Click it.
- Under the Recovery Menu, click Reset PC.
- You have to choose between two options. Keep My Files & Remove Everything.
- After selecting an option, you will proceed to the next window, where you have to choose between Cloud Download or Local Reinstall.
- After that, click Next to initiate the reset process.
Note: Even if you choose the Keep My Files option, it is best to make a backup of all your files beforehand. Just in case something goes wrong. If you don’t have a valid backup system, use a cloud-based storage service or an external drive.
For Windows 10
This is for Windows 10 users only. It is slightly different.
- Open Windows Settings and navigate to the Update & Security option.
- Select the Recovery option on the left side of the window.
- On the right side, click on Get Started under Reset This PC.
- After this point, you have to choose between Keep My Files and Remove Everything.
- If you choose the Keep My Files option, you just have to wait a bit as the system prepares, and then you will be asked to review the changes. On the other hand, if you choose the Remove Everything option, you have to choose between Just Remove My Files and Remove Files and Clean the Drive. If you just want to delete the files, click the first option. If you want to clean up the drive, then use the second option.
- After a few moments, you have to click on the Reset option to initiate the process.
Note: As discussed earlier, be sure to create a backup, no matter which option you choose.
Reset your Lenovo laptop to factory default
Both procedures are similar overall. But Lenovo users have an upper hand with the Novo button. It provides quick access and is extremely useful for regular users who don’t have advanced Windows experience. The only downside is you need a SIM ejector tool or similar device to access it. We are prone to losing them.
How to reset Lenovo laptop FAQs
Can I reset Lenovo laptop to factory settings?
Yes, you can reset your Lenovo laptop to it’s factory settings with a couple different methods. You can do this as normal within Windows just like any other Windows laptop.
Alternatively, Lenovo laptops also benefit from the option to use OneKey Recovery to reset your laptop.
Do I lose my files when I reset my Lenovo laptop?
It is advised that you back up any important files on a flash drive or external hard drive before you reset your Lenovo laptop. A full factory reset will delete your files. However, it is possible to keep your files by using the ‘Reset PC’ option within Windows 10 and 11.




